
At the beginning of my new book, Socrates engages Geoffrey Rose to discuss one of the most fascinating conceptual questions regarding hypertension.
The question is the following: Compared to normal subjects, do hypertensive patients constitute a distinct population of patients? In other words, if we go out and measure the resting blood pressure of a large swath of the population and plot the numbers as a distribution curve, do we get two separate bell-shaped curves or just one?
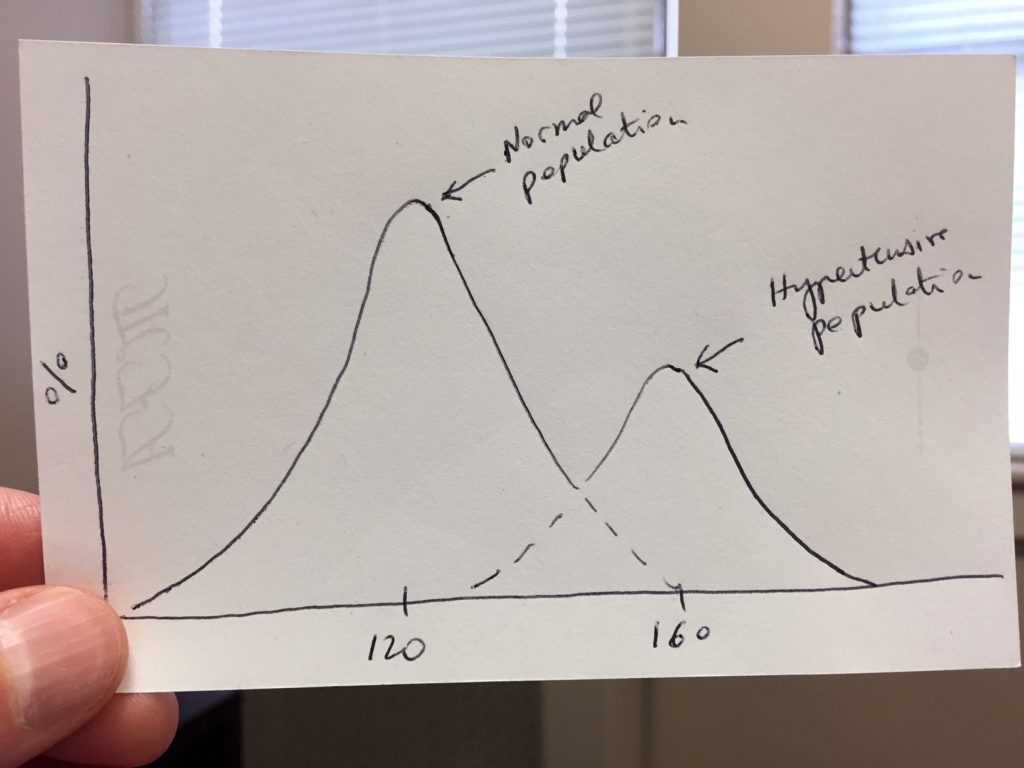
The answer to that question was the subject of an intense debate that began in the mid 1950s and lasted a couple of decades until it died down in the 1970s without any settled conclusion. Yet, an answer to that question is of critical importance not just for our understanding of hypertension, but for medical science in general and, by implication, for the direction of our healthcare system.
The reason the hypertension debate was drawn out over such a long period had to do with methodological controversies about techniques of measurement, bias toward round numbers, age and sex adjustments, etc. Furthermore, as a quantity, the blood pressure is notoriously fickle. It changes all the time!
In addition, the desire to answer the question was colored by a desire to simultaneously settle the question regarding the genetic inheritance of hypertension: Is high blood pressure passed on in Mendelian fashion?
For a while, all that researchers had to work with were plots such as the following:
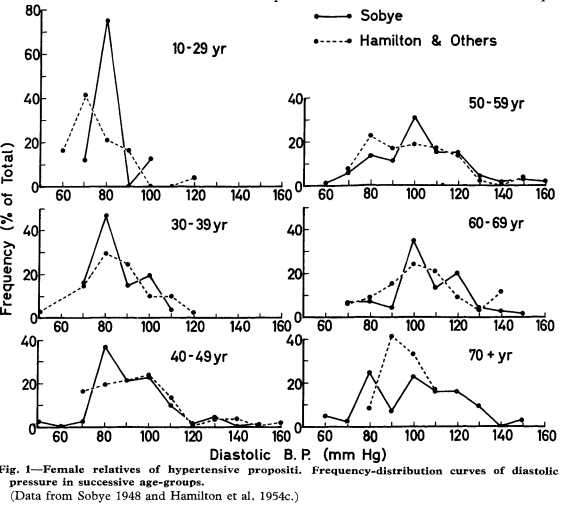
As we can see, an answer regarding the shape of the blood pressure distribution doesn’t immediately jump off the page, to say the least.
This debate on the “the nature of hypertension” was one of the most gripping medical controversy of the time. It gave rise to a legendary intellectual feud carried out over many years by two leading British physicians writing back and forth in the pages of The Lancet.

Defending the position that the blood pressure distribution is “bimodal” (i.e., is made up of two overlapping bell-shaped curves with 2 peaks, or “modes”) was Baron Robert Platt, a prominent nephrologist and, for a time, head of the Royal College of Physicians.
Platt—representing the more mainstream view—thought that hypertension was likely a genetically determined disease, and that the hypertensive population could be separated out from the normal population (albeit with some degree of overlap) if sufficiently powered studies could be conducted properly.

Opposing him was the cutting and brilliant George Pickering, a pioneer clinician scientist, who asserted that the blood pressure distribution was continuous and unimodal. According to him, there was only one hump and no evidence of a distinct hypertensive population.

The Platt-Pickering debate raged until the 1970s. On the surface, it seemed that Pickering had emerged victorious. Population studies could never clearly identify 2 separate peaks in the blood pressure distribution. Here, for example, is a schematic diagram of the systolic BP distribution in the US population derived from CDC data sets:
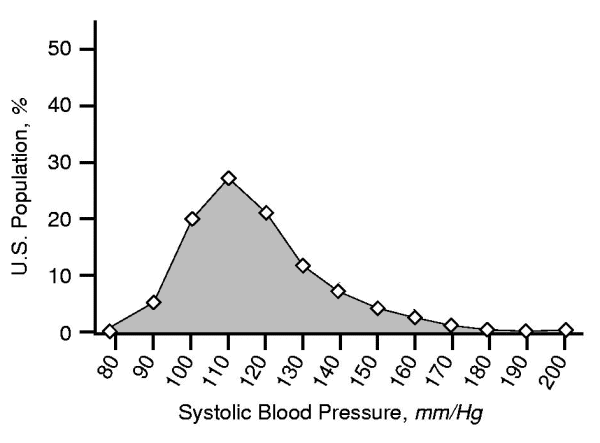
The distribution has only one hump. Note, however, that it has a “positive skew,” meaning that the distribution is asymmetric, with more people having values higher than (to the right of) the mode. This is typical of blood pressure distribution curves and, as we shall see, potentially consequential.
Pickering’s position was also favored when it became increasingly clear that high blood pressure is not genetically determined, although genetic factors undoubtedly play a role. In that sense, Platt, who thought that hypertension followed an autosomal dominant pattern of transmission (with variable penetrance), was wrong.
Today, Pickering’s claim seems commonplace. At the time, though, his was an astonishing idea because—in his own words—it pointed to the first instance of a disease “in which the defect is one of degree, not of kind, quantitative, not qualitative.”
By that phrase, Pickering meant that the “disease” hypertension was simply a designation to be applied to people who happen to be at the upper tail end of the natural blood pressure distribution curve.
Because the risk of cardiovascular complications also rises smoothly as blood pressure rises, Pickering proposed that a definition of hypertension must necessarily be an artificial construct, a matter of picking an arbitrary number above which the doctors may decide that treatment is warranted.

For Pickering, those who claim that there is an actual cut-off dividing “normotension” from hypertension commit “the fallacy of the divided line.” This idea inspired Geoffrey Rose to elaborate his theory of health and disease, a theory that took off like wildfire and now forms the basis of the population health movement.
As it turns out, the question of the modality of the blood pressure distribution (i.e., whether there are one, two, or more peaks) was never quite definitively settled by the data.
Hypertension specialist Alberto Zanchetti made that point in an insightful essay on the Platt-Pickering debate, written as part of his review of a book by JD Swales, another hypertension expert, who compiled the Lancet correspondence between the two feuding giants. According to Zanchetti, it remains possible that hypertensive patients indeed constitute a distinct population.
In the course of my research, I came across a study conducted by Professor Chris McManus in the early 1980s. At the time, Professor McManus had developed a keen interest in the problem of bi-modal and multi-modal data sets while working on problems of neuropsychology unrelated to hypertension. However, the Platt-Pickering debate was still relatively active, so he decided to have a go at shedding light on the question.
McManus knew that uniform distributions which, on the surface, have only one peak, may nevertheless represent a mixture of two or more populations, especially when the distribution is not strictly symmetrical around the peak which is invariably the case with blood pressure distribution curves. Blood pressure distribution curves, as shown above, are typically “skewed” to the right. In such cases, it is possible for a second smaller distribution to be “hiding” inside the bigger bell-shaped curve.

McManus got hold of the largest available data set on blood pressure, a data set from a study conducted in the 1950s in the city of Bergen, Norway, by Bøe et al., on a population of 68,000 subjects unadulterated by anti-hypertensive therapy. He applied the best statistical analysis at his disposal and, lo-and-behold, concluded that Platt might have been correct after all. Hypertension might very well be its own distinct thing!

The study didn’t attract much attention. First of all, he was not himself a hypertension researcher, but a physician interested in psychology and medical education. More important, drug therapy for hypertension was, by then, widespread. Clinical trials had shown that, on average, blood pressure reduction leads to fewer strokes and cardiac complications. No one cared anymore if the BP distribution was actually bi-modal or not.
But why does the question remain so important?
In immediate practical terms, it probably doesn’t make much of a difference. If there are two populations, the overlap is likely large and, at present, there is no obvious way to tell them apart.
From a scientific standpoint, however, the implications could be enormous. For example, a large overlap between the normal population and the “true” hypertensive population could explain why there is such a wide variability in the natural history of the condition and in any given person’s “response” to a certain level of pressure. A normal subject with a blood pressure chronically near 160 may behave differently from a hypertensive subject with the same baseline blood pressure. A separate hypertensive distribution curve would also suggest that many people might be treated unnecessarily based on current treatment guidelines, which rely exclusively on a cut-off number for treatment decisions.
In the future, knowing that hypertensive patients are a distinct population might guide further research to identify who does, and who does not need treatment. It would also help sort out the now intractable controversies about blood pressure targets. The blood pressure would no longer define the condition, but simply be a marker for it, i.e., be only one aspect of the phenotype of a distinct and more general cardiovascular disease, a point Herb Fred and I raised in an editorial a few years ago.
The problem, of course, is that to confirm or refute the 2-peak theory, one would likely need to perform a better statistical analysis than McManus was able to apply in the 1980s, given the rudimentary statistical tools available at the time (see technical note below).
What is missing, however, is the data set. To get a new data set today would likely be next to impossible because treatment of blood pressure is so widespread today. The only other hope, then, is to go back to the old Norwegian data.

Holding the key to the mystery of hypertension?
I contacted Professor McManus a few months ago. We had a nice email exchange which re-kindled his interest in that old problem from way back. He is very interested in trying to re-analyze the data but, unfortunately, is unable to locate it. He has searched his old computer files from the 1980s, and even made contact with Norwegian research centers, but, so far, to no avail.
So, short of putting an announcement on a milk carton, this blog post is partly a plea to anyone who would have information leading to the missing data! If you have contact with any of the authors of the 1957 Bøe et al. study , or their descendants, please let me know. It could change the course of hypertension history!
[callout]In addition to being a plea, this post is also a ploy to get you to read my book. If you found this brief retelling of the old Platt-Pickering question interesting, I invite you to check out Moving Mountains. The book gives additional details about the context and significance of the puzzle, and explains how Pickering’s answer stimulated Geoffrey Rose to elaborate his most revolutionary theory of health and disease!
Set in purgatory, the first 7 chapters feature a lively banter between Socrates and Rose, very much in the spirit of Platt-Pickering. In my opinion, there’s more thought provocation in that Socrates-Rose conversation than can be found in an entire year’s worth of current Lancet articles! :)[/callout]
Technical note:
Apart from Chris McManus’ paper, I found a study published in 1990 by Schork et al. that discusses at length the pitfalls of statistical analyses aimed at resolving the question of “mixed” distributions. Using their best techniques, the authors analyzed a much smaller data set than the data from the Bøe study used by McManus (941 versus 67,976 subjects!) and concluded for a unimodal blood pressure distribution.
Chris believes that while much of the methodological criticism mounted by Schork et al. was valid, but he thinks that they missed a very important finding in his study: In looking at the phenomenon of regression to the mean, he found that a subset of subjects regressed to a separate mean which, in Chris’ mind, is quite difficult to explain in the context of a single distribution. A re-analysis of that large data set with up-to-date tools, if feasible, seems to be what is needed.
I don’t get the significance of the “bi-modal distribution.” The question “Can hypertension be inherited?” seems to be germane only to fertile females seeking husbands who will help father their children (so that they don’t produce children who eventually become hypertensive adults). I have a hard time picturing them demanding prospective male mate’s untreated blood pressure history, or — since they are both probably in their 20’s & 30’s and still healthy — prospective male mate’s FATHER’s and maybe GRANDFATHER’s untreated blood pressure history. Both the practical & legal hurdles (personal data privacy) those females would have to surmount seem untenable.
At the end of the day, is it not enough to just have — based on as large a sample size as possible — a sequence of graphs (one each for men aged 30-35, another for men aged 35-40, . . . . . on up to men aged 75-80), where X = untreated blood pressure, Y = probability of having a stroke or heart attack? And then let each patient judge the risks of having a stroke or heart attack vs. the cost & inconvenience of various forms of treatment. No ‘threshold’ line has to be determined. The patient makes his own choice with no more than black-box science + statistics + risk management considerations.
Of course there’d be a separate set of graphs for women, assuming their stroke/heart attack vs. BP function is different.
That was a fascinating article. I never knew of this historical controversy. Two thoughts came to mind while reading this piece:
1. Determining that the distribution is intrinsically bimodal, i.e., consisting of two distinct populations, seems to require the assumption that each of the two populations have known underlying distribution functions (probably gaussian functions). Without assuming the functional form for the underlying functions, you could never distinguish the superposition of two distinct functions from a function that is asymmetric. It’s not a given that these functions are gaussian.
2. Blood pressure is not a fixed property of an individual. It varies during the day and depends on the manner in which the measurement is made. I’ve often noticed that practitioners are sloppy and do not follow measurement protocols. Some of the spread of the measured values is likely attributable to these factors. It seems unlikely that most of the statistics were collected under ideal conditions. Some of the issues are detailed here:
http://hyper.ahajournals.org/content/45/1/142.full#sec-29
Thank you, Gabriel. Both papers that I cite (by McManus and by Schork et al.) discuss the question of the BP distribution curve. As with many biological variables, my understanding is that it is usually the log transformation that is used. In regards to your second comment, it is true that the blood pressure is very fickle. Research studies usually impose a fairly strict measurement protocol on the team collecting the data. Nevertheless, problems abound. That is why some of us are of the opinion that hypertension should not be defined solely on the basis of cut-off numbers. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2929868/
Thanks for the response. I read your paper, linked in the comment, that raises the broader issue of redefining diseases and “pre” diseases to encompass ever more individuals as patients. This paper contains a list of such re-definitions that have occurred recently:
https://www.ncbi.nlm.nih.gov/pubmed/10538480
Add to that list pre-osteoporosis, which is being treated aggressively by some physicians, especially in women, with quite expensive medication.
I wondered what your thoughts were on this expansion of disease in these other areas.
I wrote about that too! https://www.ncbi.nlm.nih.gov/pubmed/20924180