An article by Diamond and Kaul in the American Journal of Cardiology outlines additional difficulties for the science of medical predictions.
Some of the problems related to HTE have been outlined by Kravitz et al., as we have previously seen, and Kent et al. offered a proposal to mitigate them. But as we noted, the proposal by Kent et al. assumes a treatment that provides fixed relative risk reduction across the range of risks. This is displayed in Panel A in the AJC paper:
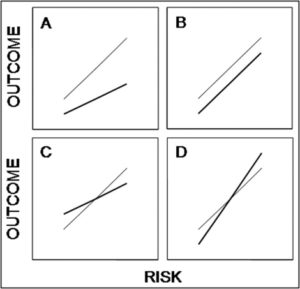
The thin line is the hypothetical baseline risk-outcome relationship, the bold line is the post-treatment risk-outcome relationship. In Panel A, the relative risk reduction is constant. As one moves from lower risk to higher risk, the absolute benefit (vertical difference between the lines) increases.
Diamond and Kaul point to the other 3 panels are possible relationships. In Panel B, absolute benefit is constant. This happens when the intervention does not influence any of the variables that determine baseline risk. They give the example of anti-platelet therapy for stent thrombosis prevention to illustrate this scenario (it’s not perfect but gives the idea).
Panel C is a case where the intervention improves a variable that determines baseline risk and worsens a variable not included in the risk assessment model. As a result, absolute risk is reduced only above a certain risk threshold. They use the example of a medication that increases HDL but worsens blood pressure, alluding to torcetrapib or such drugs. Again, the example is not very good as BP is included in baseline assessment in most models, but it conveys the idea if one only includes the lipid profile in the risk assessment.
Panel D is the opposite situation, where absolute benefit only occurs below a certain threshold because the intervention worsens a variable included in the model but improves one not included. They do not provide an example, and we can imagine such an example would be difficult to come to.
But the point of these graphs is not to illustrate how various treatments affect outcome based on a given risk assessment scale. The same graphs can equally show how various baseline risk prediction models could potentially perform (in terms of predicting treatment benefit) when a given treatment is applied. Depending on how the treatment affects the variables in the variables in the baseline risk models (as discussed above), any of the relationship A-D may be operative.
Examples of baseline risk assessment models that contain different variables are the TIMI risk score and the GRACE registry score. Theoretically, they may not predict response to a given treatment in the same way. Assuming that higher risk patients (as identified by one particular scale) have the most to gain may be faulty reasoning.
To further explore how different baseline risk assessment scales can behave differently, Diamond and Kaul take 2 different models of ICU baseline risk that individually seem to perform well (in terms of predicting risk of complications or death): The APACHE score and the MPM. They then plot their patient to patient correlation:
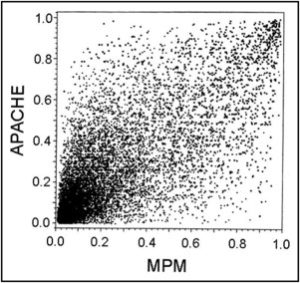
The striking lack of patient-to-patient correlation in the prediction score between the 2 models highlights the impact that the specific variables in the model have when we look at individual cases. Diamond and Kaul then conclude that in order for a single model to perform robustly, one would need to include so many variables as to make the model most certainly impractical.
To complicate matters even more, bear in mind that the discussion here looks only at predicting a certain outcome or set of outcomes, eg. cardiovascular complications. It does not address “overall benefit” across multiple outcomes, meaning that Diamond and Kaul do not address any mitigation due to harm from treatment, (so “absolute benefit” in this paper only refers to an absolute reduction in the outcome in question). Whether risk of harm from treatment is related or not to the variables in the risk model adds yet more layers of complexity.
Unsurprisingly, the authors still manage to remain optimistic about bringing quantitative methods to the bedside (ie. managed care through outcomes research) and caution against those who advocate “Wholesale abandonment of evidence-based guidelines in favor of idiosyncratic clinical judgment.”
So long as medicine is paid for by others, I don’t think guideline writers have much to fear.
[callout]Update: I wrote a letter to the editor in response to this article and inspire by the previous posts on this subject. It was kindly published by the AJC and is available as free access here.[/callout]
Diamond sets up a straw man with warning against “Wholesale abandonment of evidence based guideline….”.
James
Thanks, James. I have actually submitted a letter to the editor to the AJC on that exact point and it was accepted. I’ll keep you posted when it comes out.